当大多数AI还在结构化数据里“游泳”时,阿里通义的WebSailor已经潜入信息深海
2025年7月7日,阿里通义实验室悄然在GitHub开源了一个名为WebSailor的网络智能体。

通义大模型
短短24小时内,它登顶开源网络智能体榜单,成绩甚至超越DeepSeek R1、Grok-3等知名闭源模型。这匹黑马凭什么搅动AI江湖?
01 WebSailor的破局之战
当前AI智能体面临一个尴尬困境:处理简单问题游刃有余,一旦遭遇线索模糊、路径复杂的任务,立刻“翻车”。例如:
“世纪中期去世的基督教诗歌作者,其死亡年份恰是某科学年表的最后一年——这个年表名称是什么?”
此类问题被称为Level-3任务——不确定性极高、路径非线性,传统开源模型在此类任务上准确率趋近于零。

AI破局
WebSailor的突破性在于:在OpenAI发布的超高难度评测集BrowseComp(含1266道“地狱题”)中,其72B版本英文准确率达12.0%,超越此前最佳开源模型6.7倍,甚至直逼闭源巨头OpenAI DeepResearch。
02 技术架构三把斧
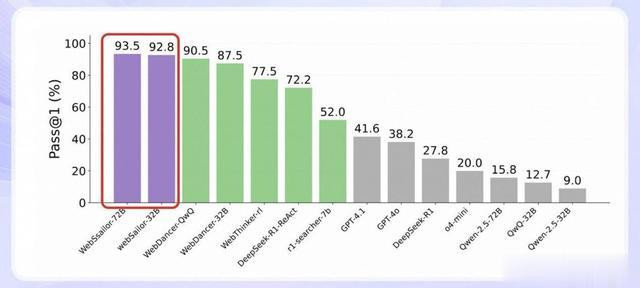
性能测试
第一斧:地狱级试炼场 SailorFog-QA
数据合成:抛弃传统线性问题链,通过知识图谱“随机游走”,生成密集交织的网状问题(如将“2015年3月15日”模糊为“2010年代中期的春季”)。
推理极限:部分问题难度极高,连OpenAI顶级模型都需调用工具40余次才能破解。
第二斧:推理逻辑
传统大模型(如Qwen、DeepSeek-R1)的推理链冗长,WebSailor做了一次“外科手术”:
抛弃原始推理文本,只保留成功的关键动作序列;
用新模型重写思考链,提炼出简洁、目标导向的逻辑。
如同将一篇散漫的散文改写为精炼的侦探笔记。
第三斧:强化学习加速器DUPO
动态筛选:自动过滤简单样本,对“差一点成功”的困难案例增加训练权重;
训练效率:相比传统方法,提速2-3倍,解决了复杂任务训练缓慢的痛点。
03 破解信息的超级侦探
在网上案例中,WebSailor展现了跨源信息整合与创造性推理能力:

AI思考
任务:“一位自称造过太阳能冰箱、住‘地图上的洞’的开发者,其父在1980年代买的第一台电脑型号是什么?”
WebSailor的行动:
锁定“地图上的洞”为关键线索;关联到开发者Joey Hess的博客及技术论坛记录;交叉验证其家庭背景与早期电脑型号;输出答案:Atari 130XE。
此类任务涉及模糊时间、匿名人物、非典型事件,传统搜索引擎几乎无能为力,而WebSailor通过多轮迭代搜索与逻辑跳跃实现了精准打击。
04 开源布局:小样本撬动大能力
WebSailor的成功颠覆了两个传统认知:

AI开源
数据质量>数据量:仅用2000+ 高质量样本冷启动,即让模型掌握复杂推理框架;
方法论>参数规模:WebSailor-7B(6.4%准确率)以1/10参数量,碾压32B级开源对手。
其技术路径——高难度合成数据 + 推理重构 + 高效RL优化——为开源社区提供了一套可复制的“能力跃迁公式”。
结语:开源智能体的分水岭
WebSailor的诞生,首次证明开源模型能在超高不确定性任务中媲美闭源系统。它不只是一个工具,更是一次宣言:在信息迷雾中,开源AI同样能成为掌舵的“水手”。

时代分水岭
目前,其完整方案已在GitHub开源,开发者可深入探索这套“思维炼金术”的代码实现。